SAGAN(Self-Attention GAN)でAnimefaceの生成
SAGAN(Self-Attention GAN)でAnimefaceの生成
8月も終了間近なので慌ててブログ書いています.
今回は,SAGANの論文に目を通したので再現実装して画像生成してみました.
~Light Weight GANを実装してたら行き詰まったなんて言えない~
8/30 Upsampling+Conv2dを使用した場合の生成画像及びアーキテクチャの画像を追記
9/25 実装したコードを追加
環境
- Intel Core i7-7700K CPU @ 4.20GHz
- GEFORCE GTX 1080
- Python 3.8.0
- Pytorch 1.9.0
- CUDA 11.1
概要
SAGANの論文[1]によれば,DiscriminatorのみにSpectral Normalizationを適用させたSNGANと違い,Generatorにも
Spectral Normalizationを適用させてやることでGAN全体の訓練の流動性が高まったとか.また,Self-Attentionは
32×32,64×64の解像で適応させることでそれぞれFID,ISがよくなったことが報告されていました.
この他にもTTUR(Two Time-scale Update Relu),Conditional Batch normalizationやHingeロスといったテクニックが用いられているみたい.今回実装したものはここ
注意点
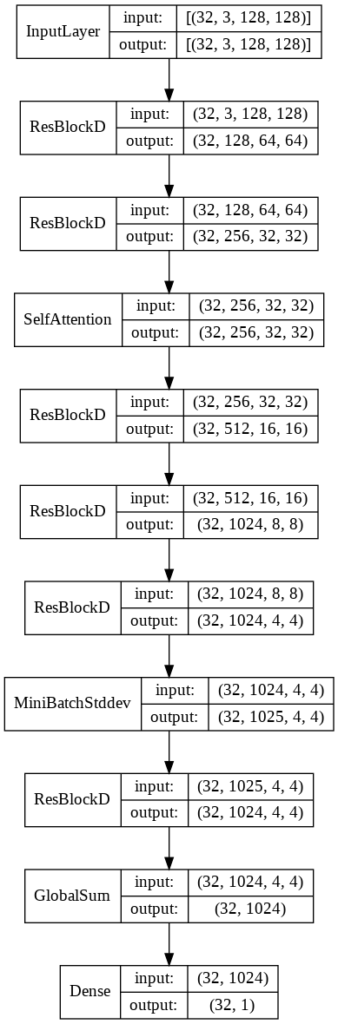
今回はUnconditionalな生成を行うためConditional Batch normalizationは普通のBatch normalizationで代用することにしました.また,PGGANで使用されたMini batch standard deviationを使用しています(詳細はPGGANの論文[2]を参照してください).
生成結果
epoch0~30















ホントはGIF貼りたかったけどファイルサイズが大きくてはれなかった…
それ以降の生成画像(30から40epoch)





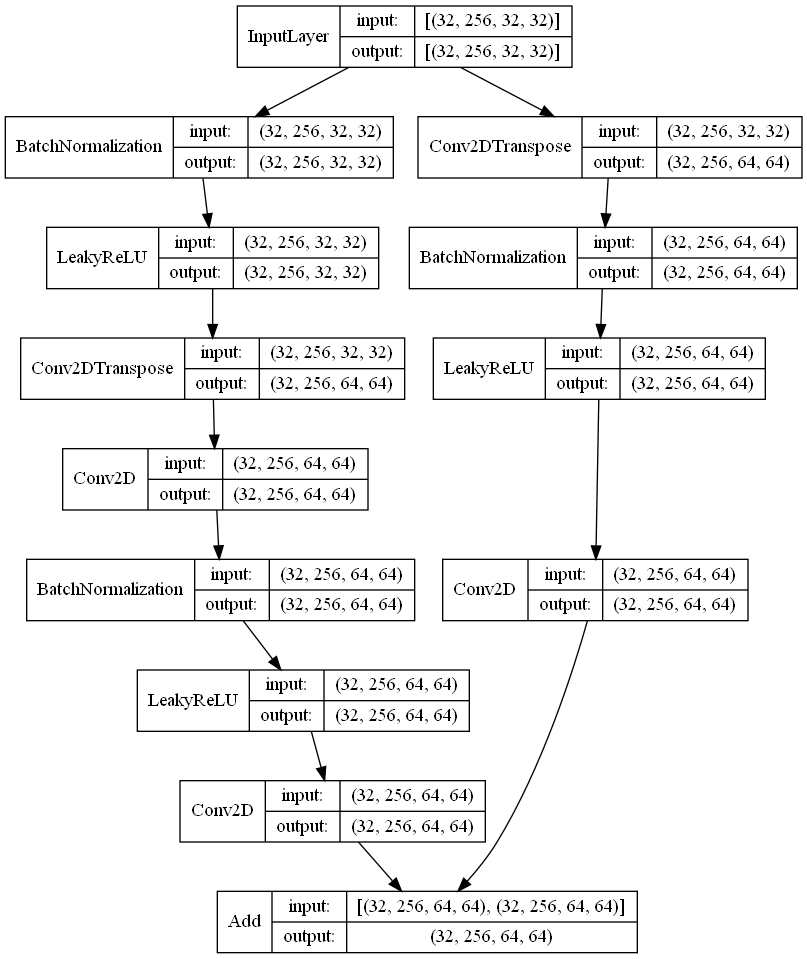
また,転置畳み込みを使用したためか,Checkerboard Artifact(画面のギザギザしたやつ)が画像に含まれているのが気になるところ…
転置畳込み層をUpsampling+畳み込みで置き換えると改善すると思うので,改善した場合は追記しようと思います.
Upsampling+畳み込みでトレーニングしてみました.





Checkerboard Artifactも目立ちにくくなっていると思います.ただ,転置畳み込みを使用したときよりも顔の輪郭が崩れている生成画像が多かった気がする.
モデル
Discriminator
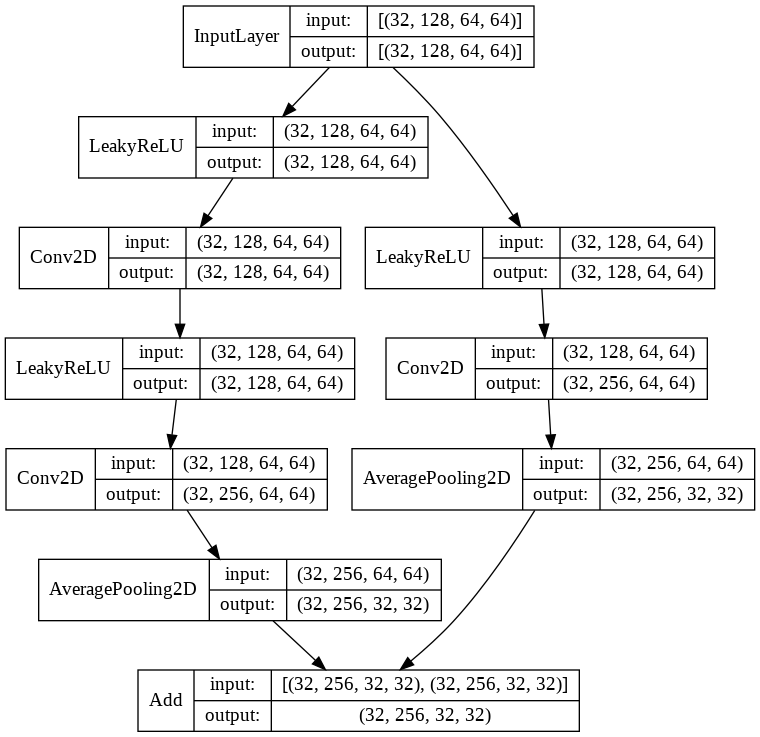
ResBlockD
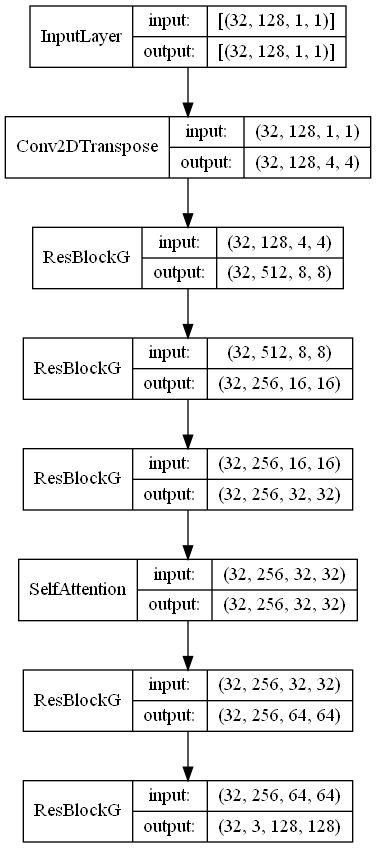
Generator
ResBlockG
終わりに
今回はSAGANを実装して遊んでみました.最近のモデルは,計算量が多くGPUのメモリに乗り切らないことがちらほらでてきちゃいました(泣)早くGPUの値段さがらないかな~
追記予定
実装するにあたっての苦労点や失敗例など(GANなどは成功例のみが公開されていることが多かったため)
参考文献
[1] Han Zhang, Ian Goodfellow, Dimitris Metaxas , and Augustus Odena. 2018.
Self-Attention Generative Adversarial Networks. arXiv preprint arXiv:1805.08318
[2] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2017.
Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv preprint arXiv:1710.10196
コメント入力