【新歓ブログリレー】Hasuraのデータ取得の仕組みがよくできている
はじめに
今年入学されるみなさん、入学おめでとうございます。
新入生に向けて
次の章以降は入学後の生活に資するものはまったくないので、興味なければ読み飛ばしてください。
アドバイスは
・授業と授業の隙間時間は埋めよう(空きコマを作るな)
・ちゃんと大学に通っている友達を5人ぐらい確保しよう
・グループワークの授業は出席していれば単位がもらえるので張り切る必要はない
・大学4年で卒業して就職する(学部就職)は大学3年から頑張らないと間に合わない
Hasuraとは
色々紹介されていますが、ざっくり言えば
「データベースの構造とGraphQL(ユーザーからの)リクエストを照合して、JSONを返してくれるミドルウェア」
です。
Hasuraを使う前に気になった点
・ 一般的にGraphQLに対応したフレームワークはN+1の対策がちょっと無理やりなので、これもそんな仕組みかどうか
・ 一定時間の間に飛んできたリクエストを強引にまとめてデータベースにクエリを投げているとか
・ GraphQLのネストしたしたリクエストが飛んできた時の認可(例えばこのユーザーはデータを返したらいけないとか)の実装が難しいのではないか
Hasuraのすごい点
・ N+1対策が無理やりではない形でなされている
・ 行レベルでこのユーザーのデータを返さない、みたいな設定ができる
N+1対策が無理やりではない形でなされている
例えばGraphQLに対応したWebフレームワークを使ってアプリケーションを開発する場合、Dataloaderのようなプラグインを導入することが一般的だと思います。
これは他の記事でも記述がありますが、多くの実装は
「生成されたSQLを即座に実行せず、一定時間クエリを貯め、SQLを1つのクエリにまとめて発行する」
というような仕組みを持っています。
これでもN+1の対策はされるのでしょうが、この強引感は個人的に好きではありません。(主観)
GraphQLとは仕組みが違うものの、似たような仕組みとしては例えばPrismaというORMで生成されるクエリはWhere INを多用する仕組みで、Prepared Statementに配置される?変数の数が多いクエリを発行した結果、PostgreSQL側で実行エラーが出ました。
しかしHasuraはこんなイけていない仕組みとは違い、あらかじめJoinされたクエリを生成してくれます。
リクエストするGraphQL
query GetActorVideo {
actor{
video_actors{
video{
id
}
}
}
}
生成されるクエリ例
SELECT
coalesce(json_agg("root"), '[]') AS "root"
FROM
(
SELECT
row_to_json(
(
SELECT
"_e"
FROM
(
SELECT
"_root.ar.root.video_actors"."video_actors" AS "video_actors"
) AS "_e"
)
) AS "root"
FROM
(
SELECT
*
FROM
"public"."actor"
WHERE
('true')
LIMIT
30
) AS "_root.base"
LEFT OUTER JOIN LATERAL (
SELECT
(
SELECT
coalesce(json_agg("_sub_query"."video_actors"), '[]')
FROM
(
SELECT
"_unnest_table"."video_actors" AS "video_actors"
FROM
UNNEST(array_agg("video_actors")) AS "_unnest_table"("video_actors")
LIMIT
100
) AS "_sub_query"
) AS "video_actors"
FROM
(
SELECT
row_to_json(
(
SELECT
"_e"
FROM
(
SELECT
"_root.ar.root.video_actors.or.video"."video" AS "video"
) AS "_e"
)
) AS "video_actors"
FROM
(
SELECT
*
FROM
"public"."video_actor"
WHERE
(("_root.base"."id") = ("actor_id"))
) AS "_root.ar.root.video_actors.base"
LEFT OUTER JOIN LATERAL (
SELECT
row_to_json(
(
SELECT
"_e"
FROM
(
SELECT
"_root.ar.root.video_actors.or.video.base"."id" AS "id"
) AS "_e"
)
) AS "video"
FROM
(
SELECT
*
FROM
"public"."video"
WHERE
(
("_root.ar.root.video_actors.base"."video_id") = ("id")
)
LIMIT
1
) AS "_root.ar.root.video_actors.or.video.base"
) AS "_root.ar.root.video_actors.or.video" ON ('true')
) AS "_root.ar.root.video_actors"
) AS "_root.ar.root.video_actors" ON ('true')
) AS "_root"
きちんとJoinするクエリが発行されていることがわかります。
(というかPostgreSQL側でJSON発行するようにしているんですねぇ~)
Joinした先のセキュリティも簡単な設定で対応できる
例えば次のようなクエリを考えてみましょう
query GetUsers{
user{
name
created_at
post{
content
created_at
}
}
}
これはユーザーに紐づいた投稿を取得するクエリですが、例えば下書きの投稿を他人から見られるのは困るとなると、発行するクエリを工夫する必要があります。
この「工夫」はよく注意しないとミスして実装し忘れるというようなことが考えられ、注意を要します。
しかしHasuraならテーブル単位で行レベルセキュリティを設定することができるため、一度設定すれば他のリレーションから該当テーブルを参照する時も適用され、実装し忘れがある程度回避できます。
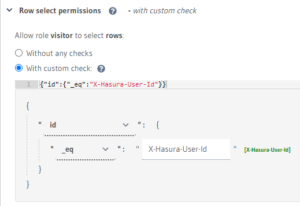
Hasuraの好きじゃないところ
メタデータの取り扱い
Hasuraは認識しているテーブルやテーブル同士の関係、行レベルセキュリティの情報をメタデータとして持っています。
このメタデータはymlファイルで持ち運ぶことができ、出力と読み込みが自在にできます。
一方で実際に実行する際はこれらのymlはデータベースのhdb_catalogというところに保存されます。
hdb_catalogのドキュメント
これがちょっと厄介で、例えばこのコンテナは古いメタデータを適用しておいて、新しいコンテナには新しいメタデータを当てておきたいみたいなことはできず、バチっと入れ替えるしかなくなっています。
一応メタデータを保存する場所はデータの保存場所と別の場所のデータベースを指定できるようです(HASURA_METADATA_DATABASE_URLを指定するようだ)が、ここは設定ファイルに忠実であってほしいと思います。
まとめ
Webアプリケーションにはデータの取得操作と更新操作の2種類ありますが、取得だけならHasuraに任せてもよさそうです。
更新処理はPrisma+Zodでも使っておけばストレスフリーに実装できるのではないでしょうか
おわり
コメント入力