IntelArcが3枚あればデカいLLMも動かせる
まえがき
芝浦祭も開催されて、今年も多くの人にゲームを遊んでもらえ、ついでに自作PC展示やらも見てもらえました.私の愛機であるDualXeon君が褒めていただけるたびに少し鼻高々になります.どうもウグイスです.
さて今回は芝浦祭期間中に動かさずに放置ではもったいないなと思い、3枚のIntelArcA770を有効活用して、デカいLLMを動かしたお話をしていこうかと思います.
環境
直近でブログにした例のマシン.
- CPU:Xeon E5-2696 v3 x 2
- MEM:128GB(16GBx8)
- GPU:IntelArcA770x3
- OS:Ubuntu24.04LTS
- Python: 3.11.10
上記の環境でやっていきます.主な使用ライブラリは以下の通り
- pytorch: 2.3.1+cxx11.abi
- Intel Extension for Pytorch: 2.3.110+xpu
- llama cpp python: 0.3.1
今回のメインはllama cpp pythonが実はXPUデバイスに対応していたという部分だったりします.
ビルドしないと入らないので、環境づくりとか含めて解説すべきなのですが、今回は報告ブログということで省略します.
モデル
gemma-2-27b-it-Q8_0.gguf
Googleが作っているGemmaというモデルを量子化したものを使用しました.
ちなみに、ファイルサイズとしては26.95GBのサイズです.
元が大きいモデルの量子化モデルの性能はなかなかいいという噂を聞いたので、試しに大手のところのやつを使ってみました.
実際のコード
今回はCLI上でやるのじゃつまらないなと思ったので、Gradioを使って簡単なWebUIをつけてみました.マジで楽なのでGradioおすすめです.AI以外の用途でもちょっと動かしたいときとかにぜひ使ってみてください.
from llama_cpp import Llama
import gradio as gr
llm = Llama(model_path="./gemma_27b/gemma-2-27b-it-Q8_0.gguf", n_gpu_layers=100)
def gen_text(prompt):
global llm
prompt=f"<start_of_turn>user\
{prompt}<end_of_turn>\
<start_of_turn>model\
<end_of_turn>\
<start_of_turn>model"
output = llm(prompt,max_tokens=2048, stop=["<end_of_turn>"], echo=True)
return output["choices"][0]["text"]
web_if = gr.Interface(fn=gen_text,
inputs=[gr.TextArea()],
outputs=["markdown"])
web_if.launch()
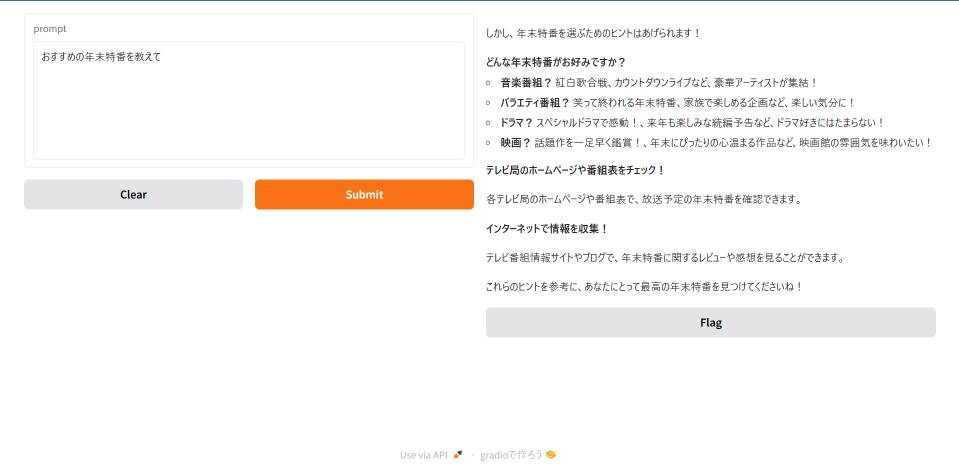
上記のプログラムを実行して、アクセスしてSubmitすると以下の画像のように生成されます.今回はGPUが複数あるのでモデルが分割されてロードされます.
あとがき
今回はデカいIntelArcが3枚あればデカいモデルも動かせるということで、実行するところまで簡単にまとめてみました.
なんかすごい短いブログになってしまいましたが、まあ気にしないでください.
ご精読ありがとうございました.また次回のブログでお会いしましょう.ウグイスでした.
コメント入力